TL;DR
RLVR fails when models can't produce correct rollouts early in training. No reward signal means no learning. CBRL fixes this exploration inefficiency by injecting few-shot examples into training prompts, more frequently at the start and over time annealing to zero. The model bootstraps new capabilities from the examples, then retains them after the examples are gone.
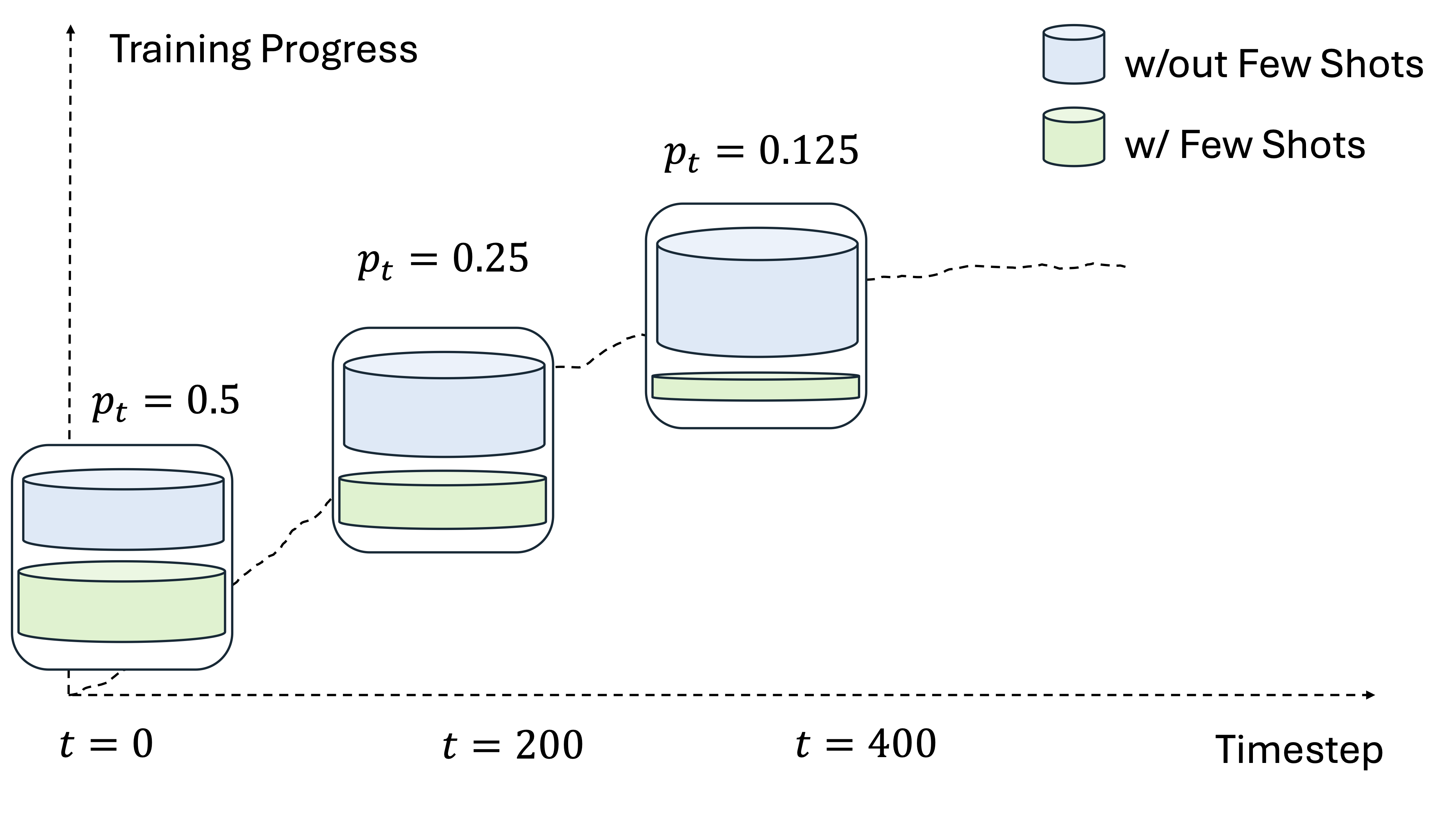
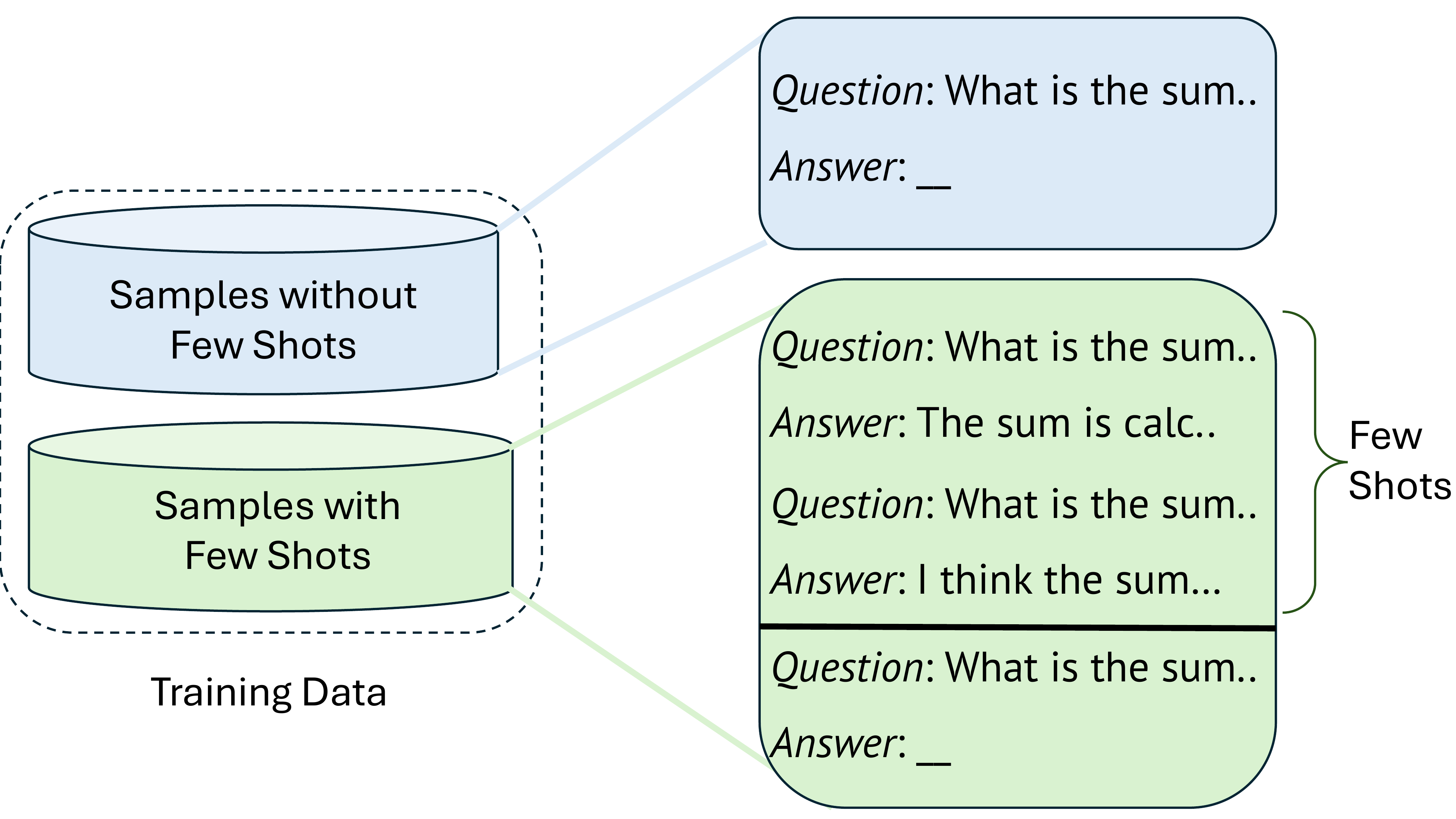
Inject Examples Early
Few-shot demonstrations are stochastically prepended to training prompts, guiding the model toward successful rollouts.
Anneal to Zero
Injection probability decreases linearly over training, forcing the model to solve problems independently.
Retain the Gains
The model internalizes the reasoning patterns. Performance persists long after demonstrations are removed.